🤖 Claude Code en Monorepos de Millones de Líneas#
¿Cómo funciona Claude Code en codebases enormes? No con RAG — con búsqueda agéntica. 🎯
🔍 El enfoque: Búsqueda Agéntica vs RAG#
Claude Code navega el codebase como un ingeniero: recorre el sistema de archivos, lee archivos, usa grep — sin índice RAG centralizado que mantener.
El problema con RAG a escala: Los embeddings no pueden seguir el ritmo de miles de commits. El índice siempre está desactualizado.
La ventaja agéntica: Cada instancia trabaja desde el codebase en vivo. Sin pipelines de embedding. Sin datos obsoletos.
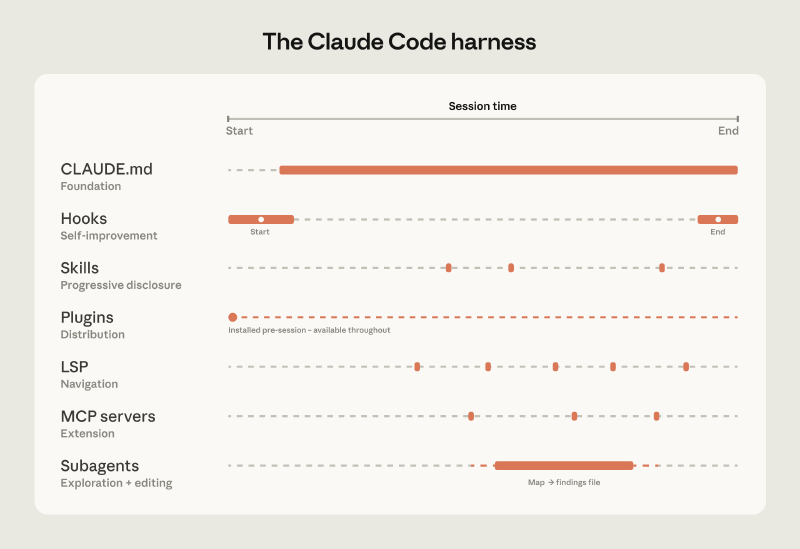
🏗️ El Harness: 5 puntos de extensión#
- CLAUDE.md — Contexto del codebase que Claude lee en cada sesión
- Hooks — Scripts que mejoran el setup continuamente (lint, formatting)
- Skills — Expertise especializado bajo demanda, sin saturar el contexto
- Plugins — Distribuyen lo que funciona a todo el equipo
- LSP integrations — Navegación a nivel de símbolo, como un IDE
💡 La clave#
“El harness importa tanto como el modelo”
El ecosistema construido alrededor del modelo determina su rendimiento más que los benchmarks.
💡 Explicación en pocas palabras#
Claude Code en codebases grandes usa búsqueda agéntica (navega el sistema de archivos en tiempo real) en lugar de RAG con embeddings — eliminando los problemas de índices desactualizados. El rendimiento depende tanto del “harness” (CLAUDE.md, hooks, skills, plugins, LSP) como del modelo subyacente. Los equipos que invierten en configurar bien el harness obtienen resultados significativamente mejores.
Más información en el link 👇

