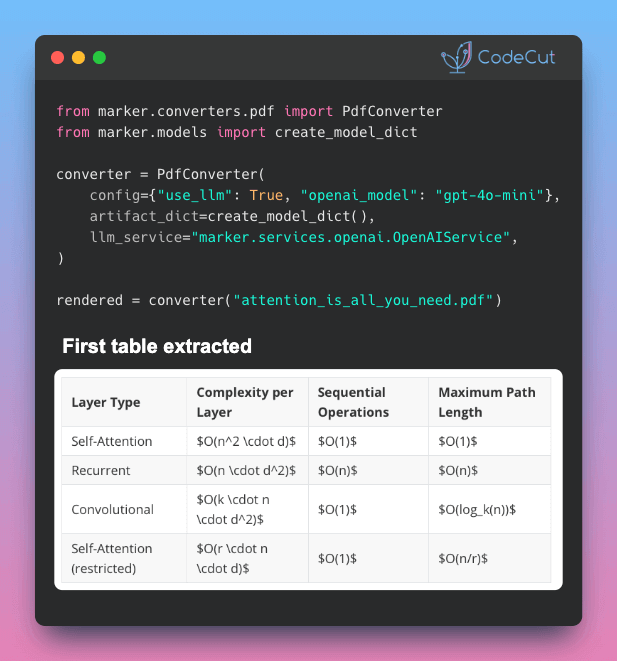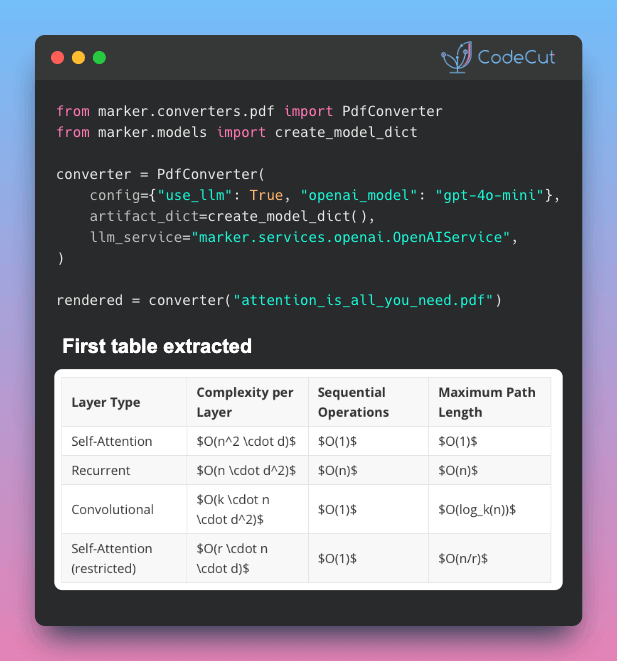
📄 El OCR estándar falla con matemáticas inline, tablas divididas entre páginas y formularios. Marker resuelve esto con un enfoque híbrido.
El problema del OCR tradicional:
- Pierde fórmulas matemáticas y LaTeX
- Divide tablas que cruzan páginas
- No entiende las relaciones entre campos de formularios
La solución de Marker: modo híbrido
En lugar de mandar todo el PDF a un LLM (lento y caro), Marker divide el trabajo:
- Pipeline de deep learning → maneja la conversión general (el trabajo pesado)
- LLM solo donde importa → entra únicamente para las partes difíciles: fusión de tablas, formateo LaTeX y extracción de formularios
Soporta OpenAI, Gemini, Claude, Ollama y Azure out of the box.
También en el newsletter:
🔹 Qdrant — motor de búsqueda vectorial construido en Rust con API Python. Modo in-memory para prototipos locales sin servidor, escala a millones de vectores en producción. Sub-segundo incluso para millones de vectores.
💡 Explicación en pocas palabras#
Marker adopta el enfoque correcto: no usar LLMs para todo (costoso), sino solo para lo que el deep learning no puede resolver bien. El resultado es extracción de PDFs precisa y escalable, ideal para pipelines RAG que necesitan ingesta de documentos de alta calidad.
Más información en el link 👇