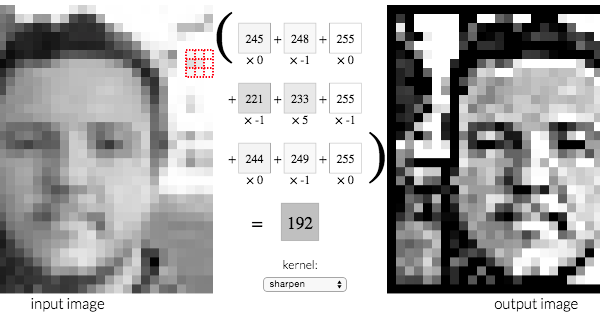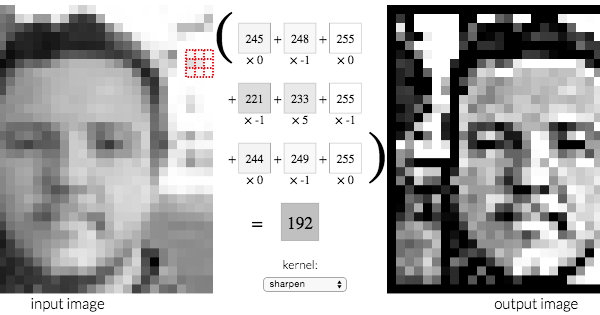
🖼️ ¿Cómo transforma una imagen el cerebro de una red neuronal? La respuesta está en los kernels.
Un kernel de imagen es una pequeña matriz 3×3 que se desliza sobre una imagen, multiplicando cada píxel por sus valores y sumando el resultado. Según los números del kernel, el efecto cambia completamente:
- 🔍 Nitidez — amplifica diferencias entre píxeles adyacentes
- 💧 Desenfoque — suaviza las diferencias, reduciendo el detalle
- 📐 Contornos — detecta bordes donde hay grandes cambios de intensidad
- 🌑 Embossing — simula profundidad mediante gradientes direccionales
Esta misma operación es la base de las Redes Neuronales Convolucionales (CNN) usadas en visión por computadora. Las redes no “ven” fotos; aplican cientos de kernels para detectar patrones: bordes, texturas, formas.
💡 Explicación en pocas palabras#
Imagina una lupa que se mueve sobre la imagen. En cada posición, multiplica los píxeles cercanos por números específicos y los suma. Si esos números detectan bordes, la lupa “ve” bordes; si detectan colores similares, “ve” regiones uniformes. Las redes neuronales aprenden automáticamente esos números para detectar lo que necesitan: ojos, objetos, texturas.
Más información en el link 👇