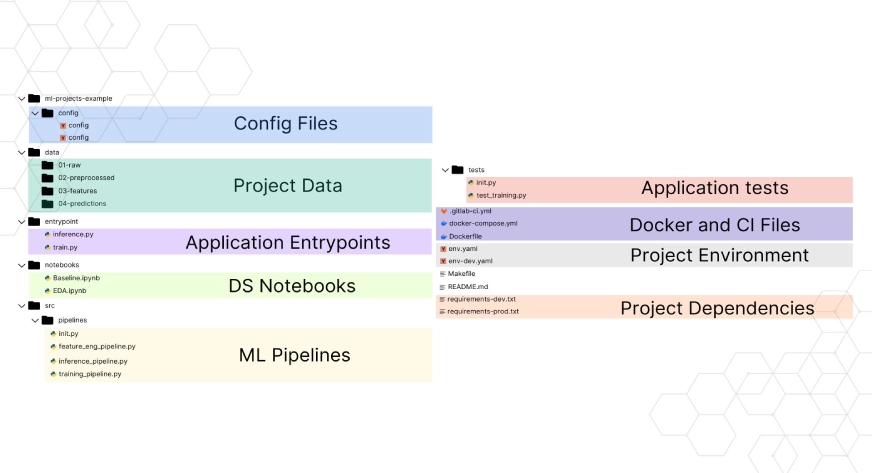
📁 ¿Tus proyectos de data science son un caos de carpetas y notebooks desordenados?
Organizar bien un proyecto no es solo una buena práctica — es lo que hace la diferencia entre un proyecto reproducible y uno que nadie (ni vos) puede entender seis meses después.
🗺️ Los 4 frameworks más usados:
CRISP-DM (Cross-Industry Standard Process for Data Mining) Ciclo iterativo: Comprensión del negocio → Datos → Preparación → Modelado → Evaluación → Despliegue. El más usado en la industria.
OSEMN (Obtain, Scrub, Explore, Model, iNterpret) Cinco pasos lógicos: obtener datos, limpiarlos, explorarlos, modelar e interpretar resultados.
KDD (Knowledge Discovery in Databases) Cubre todo el ciclo de vida: selección → preprocesamiento → transformación → minería de datos → interpretación.
SEMMA (Sample, Explore, Modify, Model, Assess) Énfasis en el desarrollo del modelo: muestra → exploración → modificación → modelado → evaluación.
⚠️ Errores comunes a evitar:
- ❌ Hardcodear rutas absolutas (
C:/Users/Juan/Downloads/data.csv) → ✅ Usar rutas relativas conpathlib - ❌ Todo en un único notebook de 100+ celdas → ✅ Jupyter solo para exploración, scripts
.pypara producción - ❌ Versionar datos en Git → ✅ Usar DVC (Data Version Control)
- ❌ Sin README → ✅ Documentar cómo instalar, obtener datos y ejecutar el proyecto
🔍 Explicación en pocas palabras
Un “framework de proceso” es simplemente un mapa de rutas para tu proyecto. Te dice qué hacer primero, qué viene después y cómo evaluar si vas bien. CRISP-DM es el más adoptado en empresas, mientras que OSEMN es más popular en academia y tutoriales. ¡La clave es elegir uno y aplicarlo consistentemente!
Más información en el link 👇