📊 ¿El modelo falló… o falló la evaluación?
Cuando un modelo de machine learning rinde peor en producción que en validación, solemos culpar al data shift — y seguimos con nuestras vidas. Pero hay una forma más inteligente de abordarlo.
🔍 El problema real: El covariate shift (cuando la distribución del dato cambia entre entrenamiento y producción) no es una excusa, es una herramienta. Si la distribución de edades en el dataset de test es distinta a la de validación, estamos comparando peras con manzanas.
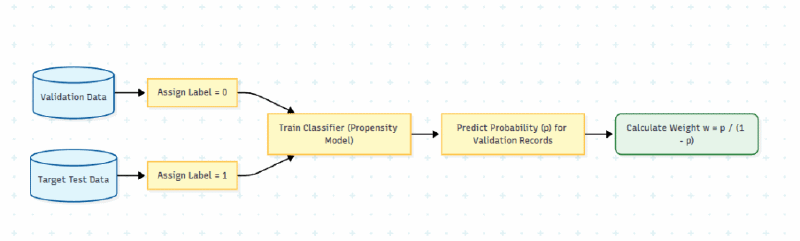
⚖️ La solución: Inverse Probability Weighting (IPW) En lugar de filtrar datos, asignamos un peso continuo a cada registro de validación para que estadísticamente “parezca” el dataset de producción:
- Peso = 1 → análisis estándar
- Peso = 0 → excluir registro
- Peso > 1 → amplificar la influencia del registro
Para múltiples variables simultáneas, se entrena un clasificador binario (propensity model) que aprende a distinguir ambos datasets. Su output de probabilidad se convierte directamente en los pesos.
💡 Explicación en pocas palabras#
Imaginá que querés saber si tu modelo funciona bien con pacientes de 50 a 80 años, pero tu dataset de validación tiene pacientes de 40 a 90. En lugar de descartar filas, le das más “importancia” a los registros similares a tu target. Así obtenés una medición honesta del rendimiento real, sin tirar datos.
✅ El resultado: tu validación ponderada se vuelve estadísticamente indistinguible del set de producción. Una forma concreta de responder: "¿el modelo está roto, o simplemente cambió el contexto?"
Más información en el link 👇

