🧠 ¿Por qué los modelos de lenguaje alucinan? Investigadores de OpenAI finalmente tienen una respuesta.
Durante años, las alucinaciones en IA fueron tratadas como un mal misterioso. Ahora, un nuevo paper de OpenAI apunta a la causa raíz: los objetivos de entrenamiento recompensan adivinar en lugar de reconocer la incertidumbre.
📊 El problema en números:
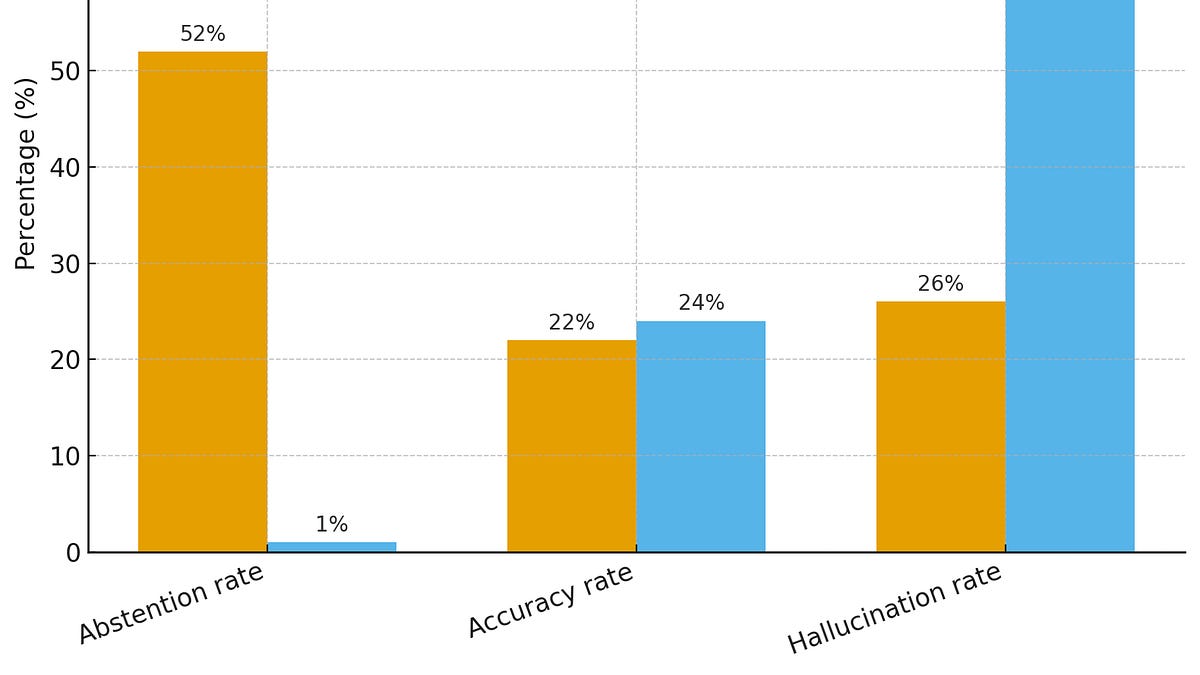
- Los modelos aprenden que intentar responder —aunque sea incorrecto— genera mejor rendimiento en benchmarks que decir “no sé”.
- Un modelo con 75% de tasa de error puede superar a otro con solo 1% de abstención, simplemente por aciertos de suerte.
🔍 Las dos causas principales:
- Pre-entrenamiento: predecir la siguiente palabra no enseña a reconocer los propios límites.
- Post-entrenamiento: los benchmarks penalizan indirectamente abstenerse, premiando la cantidad de respuestas correctas por sobre la honestidad epistémica.
🛠️ La solución propuesta: Rediseñar los benchmarks populares (GPQA, MMLU, SWE-bench) para penalizar explícitamente respuestas incorrectas y recompensar decir “no sé” cuando corresponde.
💡 Explicación en pocas palabras#
Imaginá que en un examen siempre conviene adivinar porque nunca te restan puntos. ¿Qué harías? Adivinarías todo. Los modelos de IA aprendieron exactamente eso: es más “rentable” inventar una respuesta plausible que admitir ignorancia. La solución es cambiar las reglas del examen para que mentir tenga un costo real.
⚠️ Queda un problema abierto: las situaciones fuera de distribución (OOD), donde el modelo enfrenta casos que nunca vio. Eso, por ahora, no tiene solución sencilla.
Más información en el link 👇