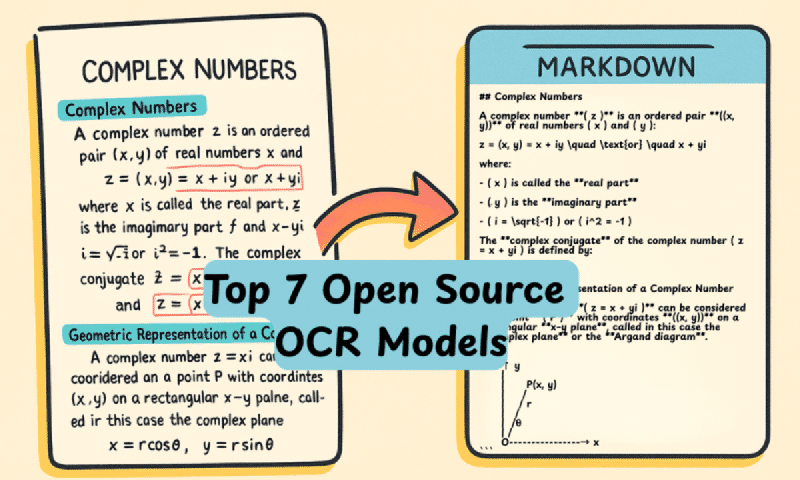
👁️ Los 7 Mejores Modelos OCR Open Source en 2025
El OCR está viviendo una revolución. Ya no se trata de extraer texto plano con errores: los nuevos modelos convierten PDFs e imágenes complejas en Markdown preciso, entendiendo tablas, fórmulas y diagramas. Todos corribles localmente.
🏆 Los 7 modelos:
- 🥇 olmOCR-2-7B — Allen Institute for AI. Mejor en ecuaciones y tablas complejas. 82.4 en olmOCR-bench.
- 🌍 PaddleOCR-VL (0.9B) — 109 idiomas (español incluido), ultra-compacto. Lidera OmniDocBench.
- 📄 OCRFlux-3B — El mejor para PDF → Markdown. Fusión de tablas entre múltiples páginas.
- 📱 MiniCPM-V 4.5 (8B) — Supera a GPT-4o y Gemini-2.0 Pro en promedio. Corre en móviles.
- ⚡ InternVL 2.5-4B — Eficiente para entornos con recursos limitados.
- 🏢 Granite Vision 3.3 (2B) — IBM. Foco en documentos empresariales, tablas y gráficos.
- 📝 TrOCR Large — Microsoft. Clásico Transformer para texto impreso simple.
💡 Explicación en pocas palabras
El OCR tradicional lee texto como si “fotografiara” caracteres individuales. Los nuevos modelos son multimodales: entienden el contexto, la estructura del documento y la semántica del contenido. ¡La diferencia es como entre un escáner básico y un asistente que lee y comprende el documento!
Más información en el link 👇
También publicado en LinkedIn.
