🤖 SkillOpt: Habilidades que se entrenan solas#
¿Y si los agentes de IA pudieran mejorar sus propios procedimientos sin modificar sus pesos?
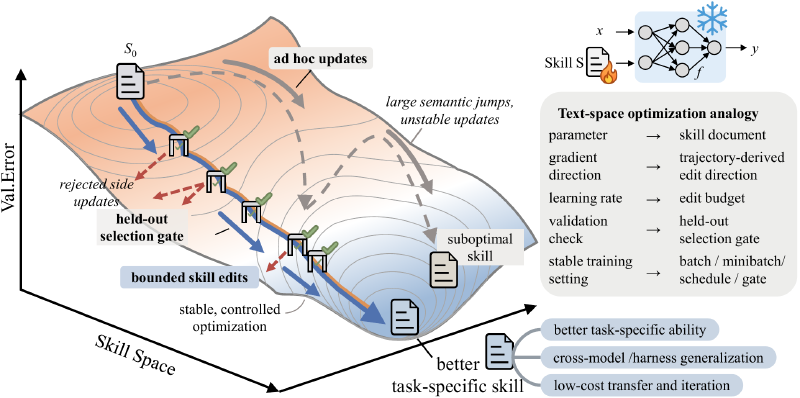
Eso es exactamente lo que propone SkillOpt, un proyecto de Microsoft Research. En lugar de hacer fine-tuning al modelo, SkillOpt optimiza un documento de texto —llamado “skill”— que le dice al agente cómo resolver tareas. 🧠
¿Cómo funciona el loop?#
- 🔄 Rollout → El agente ejecuta tareas con la habilidad actual y registra resultados.
- 🔍 Reflect → Un modelo optimizador analiza éxitos y fallos.
- ✏️ Edit → Se proponen ediciones (agregar, eliminar, reemplazar) bajo un presupuesto acotado.
- ✅ Gate → Solo se acepta el cambio si mejora el rendimiento en datos de validación.
📊 Resultados reales#
Los resultados son impresionantes:
- GPT-5.5 mejora en +23.5% de promedio en 6 benchmarks
- GPT-5.4-nano: +24.9%
- El skill exportado se transfiere entre modelos y entornos sin reentrenar
❓Algunas preguntas que me hago#
- ¿Cuál es el costo computacional real del proceso de optimización en SkillOpt?
- ¿De dónde provienen los datasets de entrenamiento y validación necesarios para el método?
- ¿Hasta qué punto generaliza un skill optimizado cuando cambia la tarea o el dominio?
- ¿Cuánto depende el rendimiento final de la potencia del modelo optimizador?
- ¿Qué tan sensible es el proceso a la elección del conjunto de validación?
- ¿Qué garantías existen de estabilidad durante el proceso de auto‑edición del skill?
💡 Explicación en pocas palabras#
Imagina que tienes un chef (el agente de IA) y una receta (el skill). En lugar de modificar las habilidades del chef, SkillOpt mejora la receta automáticamente: prueba variantes, descarta las que fallan y conserva las que funcionan. El resultado es una receta mejorada que cualquier chef puede seguir.
Más información en el link 👇
También publicado en LinkedIn.
