🤖 Claude Code in Million-Line Monorepos#
How does Claude Code work in massive codebases? Not with RAG — with agentic search. 🎯
🔍 The Approach: Agentic Search vs RAG#
Claude Code navigates a codebase like an engineer: traverses the file system, reads files, uses grep — no centralized RAG index to maintain.
The problem with RAG at scale: Embeddings can’t keep up with thousands of commits. The index is always outdated.
The agentic advantage: Each instance works from the live codebase. No embedding pipelines. No stale data.
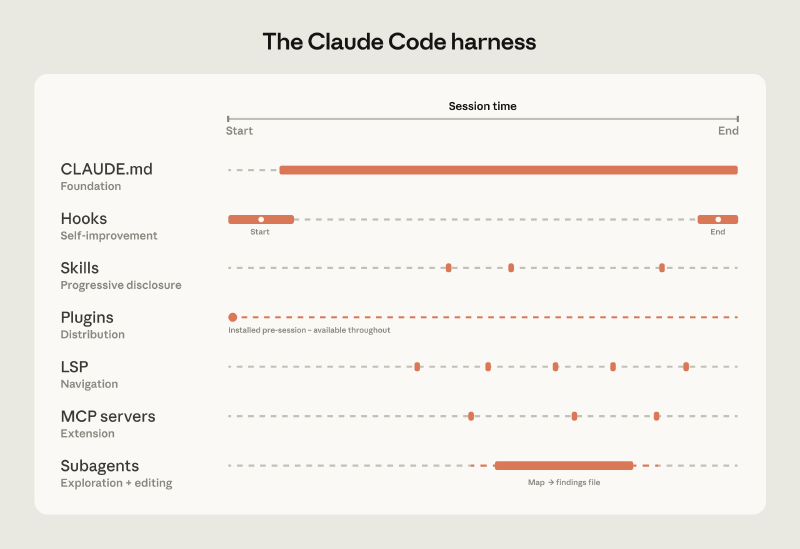
🏗️ The Harness: 5 Extension Points#
- CLAUDE.md — Codebase context Claude reads at every session start
- Hooks — Scripts that continuously improve the setup (lint, formatting)
- Skills — Specialized expertise on-demand, without bloating context
- Plugins — Distribute what works to the whole team
- LSP integrations — Symbol-level navigation, like an IDE
💡 The Key Insight#
“The harness matters as much as the model”
The ecosystem built around the model determines its performance more than benchmarks alone.
💡 Explanation in a nutshell#
Claude Code in large codebases uses agentic search (real-time file system navigation) instead of RAG with embeddings — eliminating stale index problems. Performance depends as much on the “harness” (CLAUDE.md, hooks, skills, plugins, LSP) as on the underlying model. Teams that invest in properly configuring the harness see significantly better results.
More information at the link 👇

