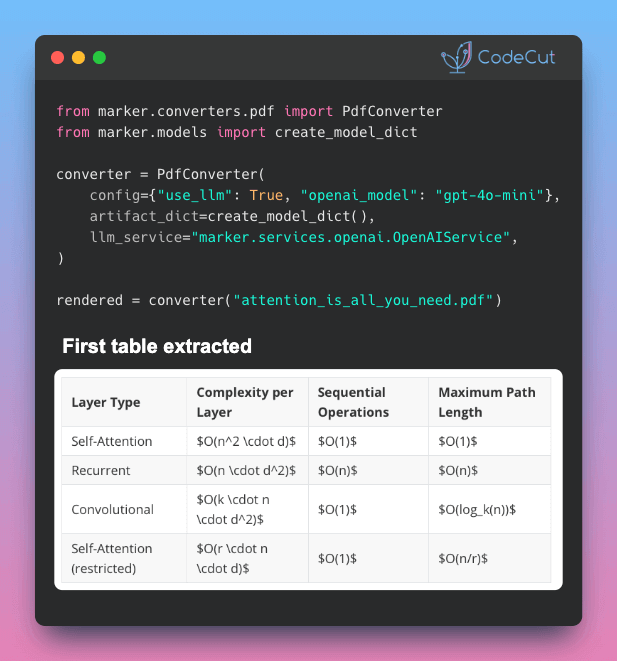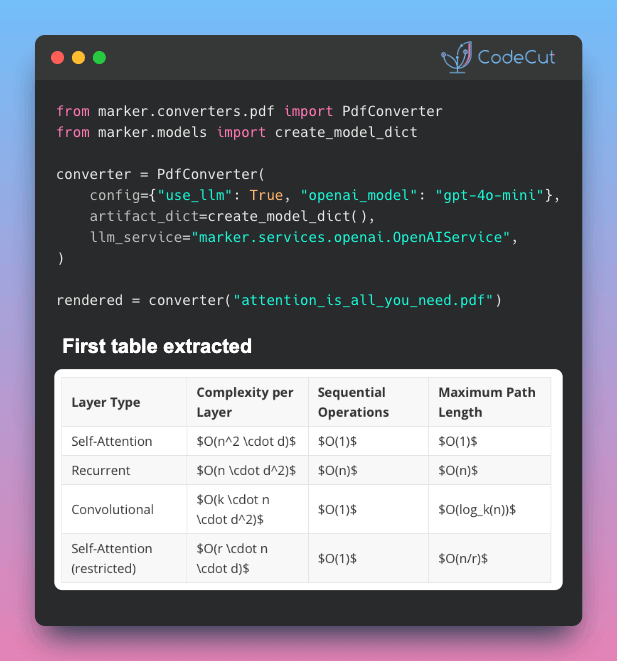
📄 Standard OCR fails with inline math, tables split across pages, and forms. Marker solves this with a hybrid approach.
The problem with traditional OCR:
- Loses mathematical formulas and LaTeX
- Splits tables that cross pages
- Doesn’t understand relationships between form fields
Marker’s solution: hybrid mode
Instead of sending the entire PDF to an LLM (slow and expensive), Marker divides the work:
- Deep learning pipeline → handles general conversion (the heavy lifting)
- LLM only where it matters → steps in only for the hard parts: table merging, LaTeX formatting, and form extraction
Supports OpenAI, Gemini, Claude, Ollama, and Azure out of the box.
Also in the newsletter:
🔹 Qdrant — vector search engine built in Rust with a Python API. In-memory mode for local prototyping without a server, scales to millions of vectors in production. Sub-second even for millions of vectors.
💡 Explanation in a nutshell#
Marker takes the right approach: don’t use LLMs for everything (expensive), only for what deep learning can’t resolve well. The result is accurate and scalable PDF extraction, ideal for RAG pipelines that need high-quality document ingestion.
More information at the link 👇