🧠 Context Engineering: The Most Important Skill for Building AI Agents
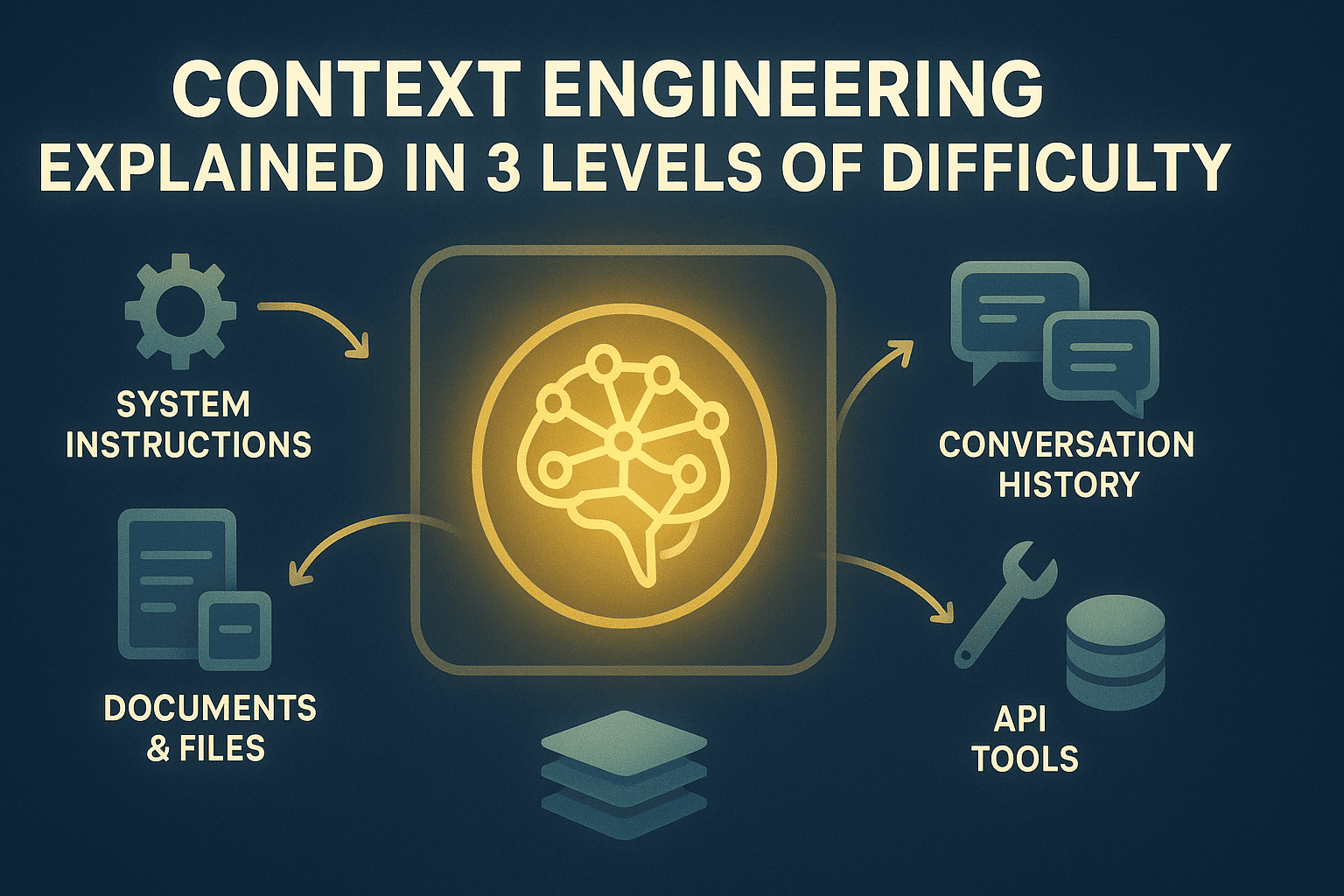
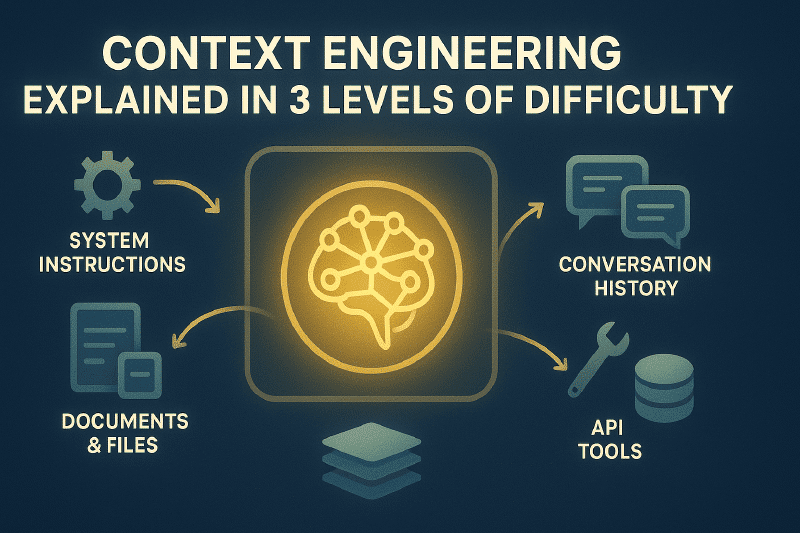
Large language models (LLMs) have a fixed context window. Everything the model “knows” at any given moment must fit within those tokens. For simple applications this is fine, but when you build an agent that makes 50 API calls, processes 10 documents, and maintains a long conversation history — without explicit management, the model starts to forget, hallucinate, and degrade.
That’s exactly what context engineering addresses: treating the context window as a managed resource, with clear policies about what enters, when, for how long, and what gets compressed or archived to external memory.
🔑 The 3 Levels Explained#
📌 Level 1 — Understanding the Bottleneck The context window is finite. Without management, important information gets randomly truncated.
⚙️ Level 2 — Optimizing in Practice Deliberately budget tokens, truncate conversations with logic, summarize tool outputs, use MCP for on-demand retrieval, and separate structured states.
🏗️ Level 3 — Advanced Architectures Tiered memory (working, episodic, semantic, procedural), extractive compression, hybrid retrieval systems (embeddings + BM25), and performance metrics.
💡 In a Nutshell#
Think of the AI model as having a fixed-size “work desk.” Context engineering is the art of deciding which papers you put on that desk at any given moment: which ones go back in a drawer, which ones get thrown away, and which ones you bring back when needed. Without this management, the desk fills up with irrelevant material and the model loses track of what actually matters.
More information at the link 👇