👁️ Top 7 Open Source OCR Models in 2025
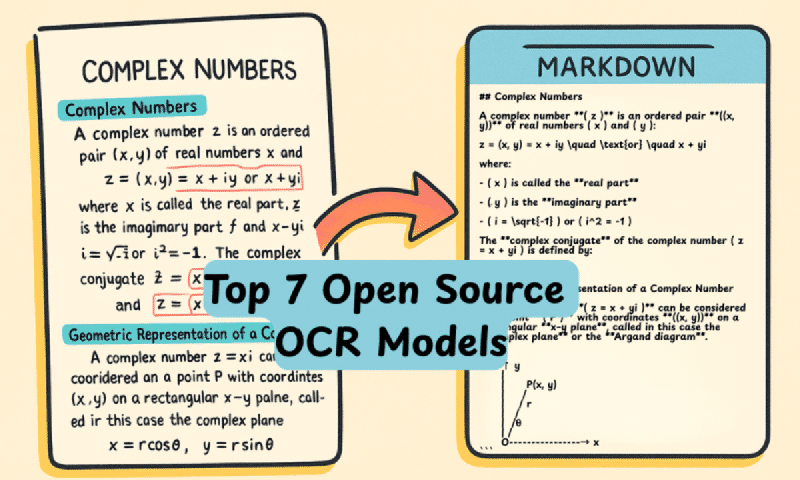
OCR is having a renaissance. We’re no longer talking about extracting plain text with errors — modern models convert PDFs and complex images into precise Markdown, understanding tables, formulas, and diagrams. All runnable locally.
🏆 The 7 models:
- 🥇 olmOCR-2-7B — Allen Institute for AI. Best for equations and complex tables. 82.4 on olmOCR-bench.
- 🌍 PaddleOCR-VL (0.9B) — 109 languages (including Spanish), ultra-compact. Leads OmniDocBench.
- 📄 OCRFlux-3B — Best for PDF → Markdown. Cross-page table and paragraph fusion.
- 📱 MiniCPM-V 4.5 (8B) — Outperforms GPT-4o and Gemini-2.0 Pro on average. Runs on mobile.
- ⚡ InternVL 2.5-4B — Efficient for resource-constrained environments.
- 🏢 Granite Vision 3.3 (2B) — IBM. Focus on enterprise documents, tables, and charts.
- 📝 TrOCR Large — Microsoft. Classic Transformer for simple printed text.
💡 Quick explanation
Traditional OCR reads text as if “photographing” individual characters. New models are multimodal: they understand context, document structure, and content semantics. The difference is like between a basic scanner and an assistant that reads and comprehends the document!
More information at the link 👇
Also published on LinkedIn.
