🕸️ Scrapling: scraping that survives site changes better#
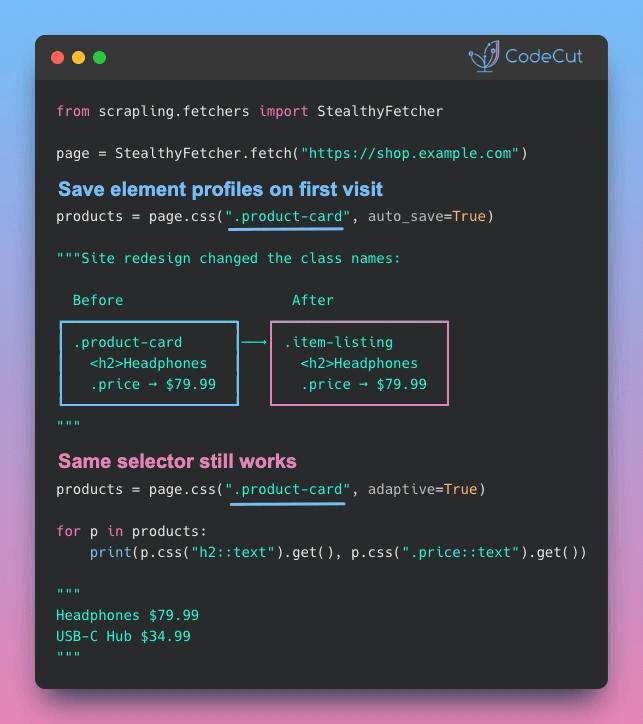
Scrapling offers a different way to do web scraping: instead of relying only on brittle CSS selectors, it stores the structure of the content so it can find it again if the site changes.
What stands out#
- 🧩 More robust than classic scraping
- 🔁 Handles layout changes better
- 🛠️ Useful for repeatable automation and extraction
- 📦 Complements BeautifulSoup rather than necessarily replacing it
It’s especially handy when the target site changes often and you don’t want to rewrite selectors all the time.
🪄 Quick explanation#
Think of a scraper with memory.
It doesn’t just know where something is today: it learns how it looked so it can find it again tomorrow.
👉 Fewer breakages, less maintenance.
More information at the link 👇

Also published on LinkedIn.
