
🚀 7 open‑source models that are changing AI coding#
These are open‑source AI models for coding without relying on cloud services.
The core idea is simple: more privacy, more control, and zero API costs.
Key takeaways:
- 🔐 Full privacy: your code never leaves your machine.
- ⚡ Powerful models: from advanced reasoning to autonomous agents.
- 🧩 MoE and huge contexts: perfect for long workflows, debugging, and complex tasks.
- 💸 Savings: if you already have good hardware, you can avoid expensive subscriptions.
🧠 TL;DR#
Imagine that instead of sending your code to external servers (like when using Copilot or Claude), you could run a “mini‑AI brain” locally on your computer.
That means:
- No one sees your code.
- Fast responses without depending on the internet.
- You can automate long tasks without limits.
These open‑source models enable exactly that: high‑level AI, but on your own machine.
🧩 Models and their main features#
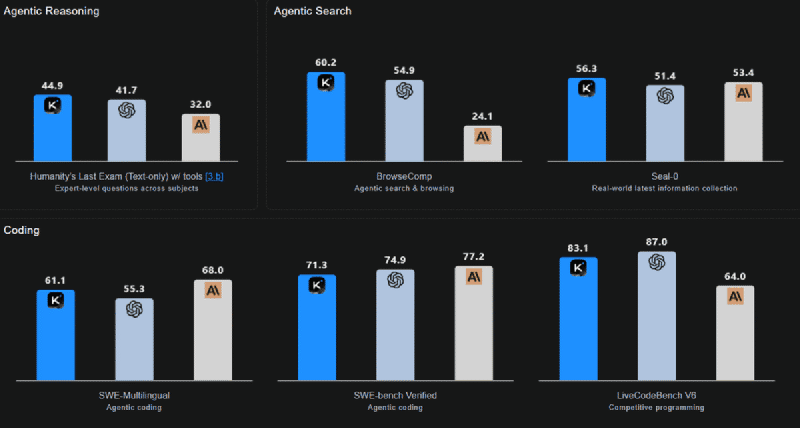
1. Kimi‑K2‑Thinking (Moonshot AI)#
- 🧠 1T‑parameter MoE (32B active)
- 🛠️ Agent with step‑by‑step reasoning
- 🔁 Maintains 200–300 tool calls without losing coherence
- 📏 Context: 256K tokens
- ⚡ INT4 optimized for low latency
- ⭐ Strong in long reasoning, multilingual, and autonomous workflows
2. MiniMax‑M2 (MiniMaxAI)#
- 🧩 230B‑parameter MoE (10B active)
- ⚡ High efficiency and low latency
- 🔄 Ideal for plan → act → verify loops
- 🎯 Built for interactive agents and coding tasks
- 💰 Optimized for cost and speed
3. GPT‑OSS‑120B (OpenAI)#
- 🧠 117B parameters, 5.1B active
- 🔧 Native tools: function calling, browsing, Python, structured outputs
- 🎚️ Configurable reasoning levels
- 🧪 Full fine‑tuning available
- 🥇 High performance in benchmarks, reasoning, and tool use
4. DeepSeek‑V3.2‑Exp (DeepSeek AI)#
- 🧠 671B parameters, 37B active
- 🧵 Introduces DeepSeek Sparse Attention (DSA)
- 📏 128K token context
- 🎯 Optimized for long‑sequence efficiency
- 🔬 Performance similar to V3.1 but with efficiency gains
5. GLM‑4.6 (Z.ai)#
- 🧠 355B parameters, 32B active
- 📏 Extended context to 200K tokens
- 💻 Clear improvements in coding and frontend generation
- 🔧 Better integration with agents and tools
- 🥇 Competitive against DeepSeek‑V3.1 and Claude Sonnet 4
6. Qwen3‑235B‑A22B‑Instruct‑2507 (Alibaba Cloud)#
- 🧠 235B parameters, 256K tokens
- 🎯 No‑thinking model: direct answers without showing reasoning
- 🌍 Strong in multilingual, logic, math and coding
- 🧰 Improvements in tool use and alignment with user preferences
- 🏢 Ideal for practical, production tasks
7. Apriel‑1.5‑15B‑Thinker (ServiceNow AI)#
- 🧠 15B parameters (very compact)
- 👁️ Multimodal: text + images
- 📏 ~131K token context
- ⚙️ Continuous training on text and images
- 🏭 Excellent for enterprise agents and DevOps
More information at the link 👇

Also published on LinkedIn.
